Monday, April 20, 2015
cubeSavvy Utilities 2.0 - File Filters
Head on over to cubeSavvy to see the extremely helpful new feature I just added for filtering files using Essbase member selections.
Sunday, March 29, 2015
cubeSavvy Utilities – updated MDX capabilities
As promised when I introduced cubeSavvy Utilities, expanding the MDX Query functionality to handle PROPERTIES and PROPERTY_EXPR was my next task.
I’m happy to say that version 1.1, now available for download, incorporates this feature.

This version can also handle an empty Columns axis:
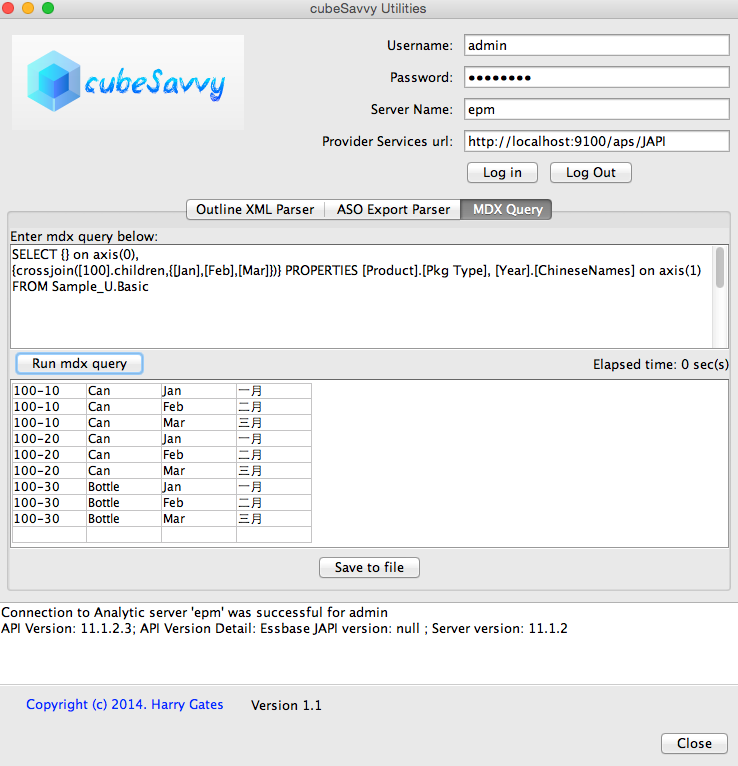
Or an empty Rows axis:
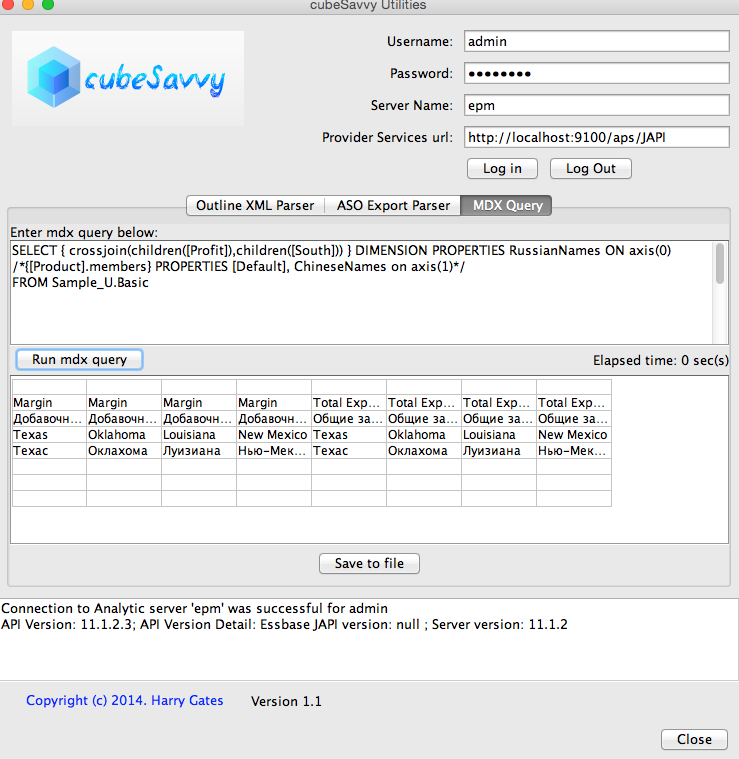
As you can see above, this gives you the ability to specify whatever you want in a Column or Row – and even by Dimension. Below is the MDX query from the empty Columns axis screenshot above. Note how I specify [Pkg Type] for the Product dimension property, but [ChineseNames] for Year.
SELECT {} on axis(0),
{crossjoin([100].children,{[Jan],[Feb],[Mar]})} PROPERTIES [Product].[Pkg Type], [Year].[ChineseNames] on axis(1)
FROM Sample_U.Basic
{crossjoin([100].children,{[Jan],[Feb],[Mar]})} PROPERTIES [Product].[Pkg Type], [Year].[ChineseNames] on axis(1)
FROM Sample_U.Basic
This flexibility gives you the power to control exactly what you want to see in the rows and columns. Therefore, I removed the 3 “Display Alias” checkboxes that were in the first version. Now you can let your MDX query do the talking. I love MDX and XMLA!
Happy querying!
Wednesday, March 25, 2015
Introducing cubeSavvy Utilities
cubeSavvy Utilities
I’ve wanted to combine my various Essbase-related tools into a single, integrated tool for a while. That tool is now called cubeSavvy Utilities. It encompasses my MDX Query Tool – XMLA Edition, ASO Export Parser, and MaxL Outline XML Parser.
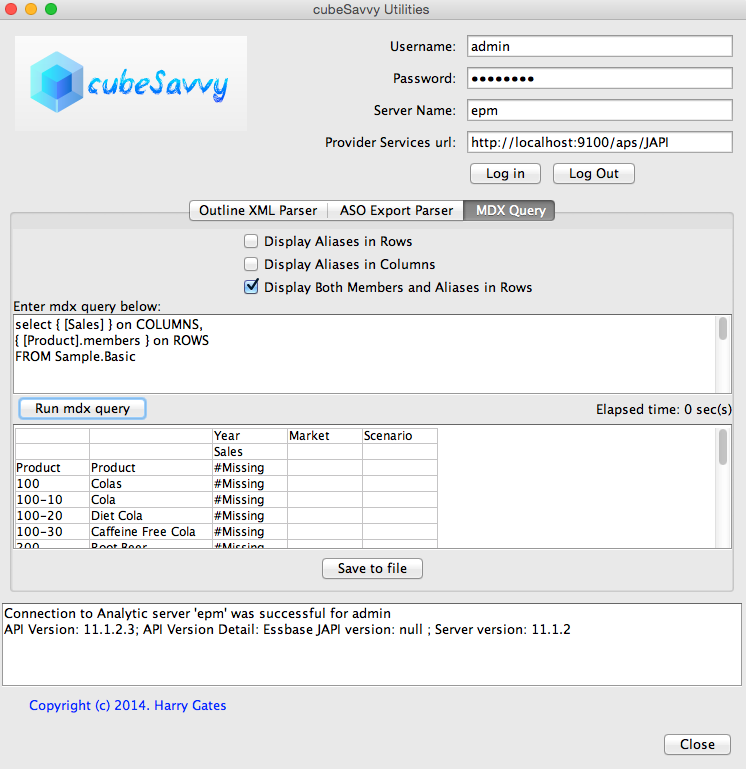
I’ve also made some enhancements to the MDX Query tool’s functionality. The most obvious is the new ability to ‘Display Both Members and Aliases in Rows’, as seen below. However, it can also now handle queries that either have just COLUMNS or just ROWS. The next version will have expanded capability to display DIMENSION PROPERTIES and PROPERTY_EXPR. These are currently just ignored.
All 3 functions have been made scriptable, with the addition of a cubeSavvyUtilities.conf configuration file to specify the same parameters found in the GUI version. The configuration file also stores Essbase server information, like user name, password, server name, and APS url. I’m extremely security conscious, so the password is stored in encrypted format. Just enter it the first time and it’s encrypted for future uses. Running from the command-line/script is as easy as: java -jar cubeSavvyUtilities.jar out. The possible flags are ‘aso’ (for the ASO Export Parser), ‘out’ (for the XML Outline Parser), and ‘mdx’ (for the MDX Query Tool).
Following are the contents of a sample cubeSavvyUtilities.conf file:
#——————————————————————————-
#cubeSavvy Utilities, copyright 2015. Harry Gates
#Place quotation marks around entries:
# ASOExportParser.FileToParse=”C:\\Documents and Settings\\harry\\asosamp.txt”
# OR
# ASOExportParser.FileToParse=”C:/Documents and Settings/harry/asosamp.txt”
#To enter new Essbase.Password
#1) Enter new password value in line: Essbase.Password=”newPassword”
#2) Set: Essbase.PasswordEncrypted=false
#3) Essbase.PasswordEncryped will be set to true the first time the program is run as a script
#To specify filters:
# ASOExportParser.Filters=[“<DESC/Qtr1″,”<DESC/Senior”,”<CHILD/Digital Cameras”]
#To specify no filters, you can delete everything after the equals sign on the line: ASOExportParser.Filters=
#The MDX Query can span multiple lines by surrounding it with three quotation marks as follows:
# MDXQuery.MDXStatement=”””
# SELECT CrossJoin([Measures].CHILDREN, [Market].CHILDREN) on columns,
# Product].Members on rows
# from Sample.Basic
# “””
Essbase.APSUrl=”http://localhost:9100/aps/JAPI”
Essbase.ServerName=”epm”
Essbase.UserName=”admin”
Essbase.Password=”password”
Essbase.PasswordEncrypted=false
#——————————————————————————-
#cubeSavvy Utilities, copyright 2015. Harry Gates
#Place quotation marks around entries:
# ASOExportParser.FileToParse=”C:\\Documents and Settings\\harry\\asosamp.txt”
# OR
# ASOExportParser.FileToParse=”C:/Documents and Settings/harry/asosamp.txt”
#To enter new Essbase.Password
#1) Enter new password value in line: Essbase.Password=”newPassword”
#2) Set: Essbase.PasswordEncrypted=false
#3) Essbase.PasswordEncryped will be set to true the first time the program is run as a script
#To specify filters:
# ASOExportParser.Filters=[“<DESC/Qtr1″,”<DESC/Senior”,”<CHILD/Digital Cameras”]
#To specify no filters, you can delete everything after the equals sign on the line: ASOExportParser.Filters=
#The MDX Query can span multiple lines by surrounding it with three quotation marks as follows:
# MDXQuery.MDXStatement=”””
# SELECT CrossJoin([Measures].CHILDREN, [Market].CHILDREN) on columns,
# Product].Members on rows
# from Sample.Basic
# “””
Essbase.APSUrl=”http://localhost:9100/aps/JAPI”
Essbase.ServerName=”epm”
Essbase.UserName=”admin”
Essbase.Password=”password”
Essbase.PasswordEncrypted=false
ASOExportParser.Application=”ASOsamp”
ASOExportParser.Database=”Sample”
ASOExportParser.FileToParse=”asosamp.txt”
ASOExportParser.OutputFile=”outputConf.txt”
ASOExportParser.Filters=[“<DESC/Qtr1″,”<DESC/Senior”,”<CHILD/Digital Cameras”,”<DESC/Sale”,”<CHILD/Price Paid”,”<DESC/Original Price”]
ASOExportParser.Database=”Sample”
ASOExportParser.FileToParse=”asosamp.txt”
ASOExportParser.OutputFile=”outputConf.txt”
ASOExportParser.Filters=[“<DESC/Qtr1″,”<DESC/Senior”,”<CHILD/Digital Cameras”,”<DESC/Sale”,”<CHILD/Price Paid”,”<DESC/Original Price”]
OutlineParser.FileToParse=”/Users/harry/test_124.xml”
OutlineParser.OutputFile=”/Users/harry/out124.txt”
OutlineParser.FieldDelimiter=”|”
OutlineParser.OutputFile=”/Users/harry/out124.txt”
OutlineParser.FieldDelimiter=”|”
MDXQuery.OutputFile=”/Users/harry/mdxResult.txt”
MDXQuery.DisplayAliasInRows=false
MDXQuery.DisplayMemberAndAliasInRows=true
MDXQuery.DisplayAliasInColumns=false
MDXQuery.MDXStatement=”””
SELECT CrossJoin([Measures].CHILDREN,[Market].CHILDREN) on columns,
[Product].Members on rows
from Sample.Basic
“””
#——————————————————————————-
MDXQuery.DisplayAliasInRows=false
MDXQuery.DisplayMemberAndAliasInRows=true
MDXQuery.DisplayAliasInColumns=false
MDXQuery.MDXStatement=”””
SELECT CrossJoin([Measures].CHILDREN,[Market].CHILDREN) on columns,
[Product].Members on rows
from Sample.Basic
“””
#——————————————————————————-
I originally developed each of these tools to scratch my own Essbase development and administration “itches”, where Oracle had yet to provide a solution. I hope you find them useful, too.
You can download cubeSavvy Utilities here.
Please let me know if you have any questions or ideas for improvement. I can be reached at harry.gates@cubesavvy.com
Sunday, September 28, 2014
Parse ASO export to columns
I developed MDX Query Tool in order to facilitate extracting small amounts of data from ASO databases using MDX queries. Sometimes, however, the volume of data you are working with exceeds the MDX query limit. You may be able to craft an optimized report script to work around this limitation. Other times the window required by your service-level agreement with clients is simply shorter than the time it takes to run the mdx query. Chances are report scripts are not going to be much help in this situation. Judging by the 151 posts on Network54 related to ASO exports in column format, many others have also come to this conclusion.
Now we know that running a level-0 export from an ASO cube is extremely fast. For example, I've been able to export cubes with 10GB dat files in less than a minute. The problem is that the output is in a format optimized for loading back into Essbase, not for querying or grepping. Having run into this roadblock recently, I've created a utility to parse this format into the same format as a BSO level-0 column export.
Click here to download the Parse ASO export to columns tool.

Follow these steps to use the tool:
Now we know that running a level-0 export from an ASO cube is extremely fast. For example, I've been able to export cubes with 10GB dat files in less than a minute. The problem is that the output is in a format optimized for loading back into Essbase, not for querying or grepping. Having run into this roadblock recently, I've created a utility to parse this format into the same format as a BSO level-0 column export.
ASO level-0 export format (default is tab-delimited)
"Account_A" "Account_B" "Account_C" "Account_D" "Jan" "Actual" "CurrentVersion" "FY09" "Entity_A" "Dept_A" "LC_01" "PR_00" "PJ_00" "ICP_000" 94678.7 "Dept_B" -2538.48
Output from tool (also tab-delimited)
"Account_A" "Jan" "Actual" "CurrentVersion" "FY09" "Entity_A" "Dept_A" "LC_01" "PR_00" "PJ_00" "ICP_000" 94678.7 "Account_A" "Jan" "Actual" "CurrentVersion" "FY09" "Entity_A" "Dept_B" "LC_01" "PR_00" "PJ_00" "ICP_000" -2538.48
Click here to download the Parse ASO export to columns tool.
Follow these steps to use the tool:
- After downloading the zip file, just unzip it and double-click on the ASOColumnarExport.jar file to launch the GUI.
- As you can see in the screenshot above, you will need to select the file location to which you've already saved the exported ASO database. I can make this step part of the tool, but for now I wanted it to be as flexible as possible. If you'd like this as an option, let me know.
- Make sure the Application (e.g. ASOsamp) and Database (e.g. Basic) match the export file that you selected. Otherwise the process will error out.
- Fill in information for the other fields as necessary.
- Click the "Parse to columns" button to run the process. A status bar will be display the parser's progress and will notify you when the process is completed.
Wednesday, April 2, 2014
MDX Query Tool - XMLA Edition
Response to the MDX Query Tool has been overwhelmingly positive. My sincere thanks for the emails and comments. They keep me motivated to continue making useful tools. There's nothing quite so discouraging as releasing a tool, only to have no one use it.
Several people, however, experienced the phenomenon of JAR hell, caused by the version of the ess_es_server.jar file in the lib directory. The version here has to exactly match the version of Provider Services running on the server from which you want to retrieve data. I recommended that you find the version on your server and copy it to the MDXQuery/lib folder. This felt like a hack, however, so I started thinking about ways to eliminate this requirement.
Like most Essbase developers, in the back of my mind I knew that Essbase supported XMLA, but had never really thought about using it - until now. The main appeal at first was that no Essbase-specific jars are needed. However, as the Wikipedia article on XMLA states, "XML for Analysis (abbreviated as XMLA) is an industry standard for data access in analytical systems, such as OLAP and data mining." It's used by other vendors (Microsoft, Pentaho, SAS) in other OLAP products besides Essbase (MS Analysis Services, Pentaho/Mondrian - open-source, Jedox - open-source). I don't have any of these products installed, but theoretically at least, you could point this version of the MDX Query Tool to them and it should work. Please let me know in the comments if you do this and whether or not it works.
After launching the MDXQueryXMLA.bat|sh file, you'll need to input the appropriate parameters for your environment, as seen below. The sharp-eyed will notice that there are no longer fields to enter Application and Cube information. This is not necessary through XMLA, since the MDX expression already contains this information in the FROM statement. For this reason alone I like it better than the Essbase Java API version that uses IEssOpMdxQuery.
Happy MDX querying!

Sunday, March 16, 2014
MDX Query Tool
I really like MDX. Its syntax and power make it an invaluable tool in any Essbase professional's tool-kit. However, Hyperion/Oracle has not made a very user-friendly way to output MDX queries. You can use MaxL to output the results, but then you have to parse all the extraneous bits to make the result useful. You can use EAS to view the results of your MDX query, but there's no way to copy the data table to use somewhere else.
Therefore, I put together a GUI utility that uses the Essbase Java API to output the result of an MDX query to a table that can then be saved to a file. The file is tab-delimited, so it can easily be imported to Excel. The tool is ever so aptly named the MDX Query Tool. Hey, I'm an Essbase geek, not a marketing guru! If anyone else has a better name, I'm willing to rebrand the tool posthaste.
You can download the MDX Query Tool from my Google drive, no Google account needed. As you can see, there are two files to launch: MDXQuery.bat (for Windows) and MDXQuery.sh (for the superior operating systems). As a zip file cannot maintain file permissions, you'll need to 'chmod a+x MDXQuery.sh' on *NIX and Mac OS X. Please use cubeSavvy Utilities, which has improved functionality for displaying MDX properties. You can download it here.
Once unzipped, you'll see a lib directory. The ess_es_server.jar file included with the MDX Query Tool is for version 11.1.2.3. If you're on a different version, you'll need to find the ess_es_server.jar in your install and copy it to the lib directory. For example, it resides in ORACLE_HOME/common/EssbaseJavaAPI/11.1.2.0/lib in my 11.1.2.3 installation.
After launching the MDXQuery.bat|sh file, you'll need to input the appropriate parameters for your environment, as seen below:
 Clicking on the "Save to file" button at the bottom will open a dialog box that will allow you to choose a file path/name for the file. You can then open this file, copy the contents, and paste directly to Excel. If there is demand, I will add the ability to copy the results directly from the table to the clipboard. Just let me know in the comments.
Clicking on the "Save to file" button at the bottom will open a dialog box that will allow you to choose a file path/name for the file. You can then open this file, copy the contents, and paste directly to Excel. If there is demand, I will add the ability to copy the results directly from the table to the clipboard. Just let me know in the comments.
I hope this tool makes it easier for you to work with MDX queries.
Therefore, I put together a GUI utility that uses the Essbase Java API to output the result of an MDX query to a table that can then be saved to a file. The file is tab-delimited, so it can easily be imported to Excel. The tool is ever so aptly named the MDX Query Tool. Hey, I'm an Essbase geek, not a marketing guru! If anyone else has a better name, I'm willing to rebrand the tool posthaste.
Once unzipped, you'll see a lib directory. The ess_es_server.jar file included with the MDX Query Tool is for version 11.1.2.3. If you're on a different version, you'll need to find the ess_es_server.jar in your install and copy it to the lib directory. For example, it resides in ORACLE_HOME/common/EssbaseJavaAPI/11.1.2.0/lib in my 11.1.2.3 installation.
After launching the MDXQuery.bat|sh file, you'll need to input the appropriate parameters for your environment, as seen below:
I hope this tool makes it easier for you to work with MDX queries.
Monday, February 17, 2014
Planning Calc Manager Rules - performance monitor
Sometimes I get comments from users that "Planning performance seems slow". The first thing I do in such instances is run the SQL code below to determine if there's an issue with Calc Manager rules running too long. Both the Oracle and SQL Server versions below calculate the "average time in seconds" (avg_time_seconds) and the "maximum time in seconds" (max_time_seconds) for each Calc Manager rule, producing a table similar to the following:
Oracle:
SQL Server:
| job_name | num_times_run | avg_time_seconds | max_time_seconds |
|---|---|---|---|
| AllocateBudget | 45 | 25 | 50 |
| AllocateForecast | 15 | 28 | 32 |
Oracle:
select job_name, count(job_name) as num_times_run, round(avg(abs(extract(second from elapsed) + extract(minute from elapsed)*60 + extract(hour from elapsed)*60*60 + extract(day from elapsed)*24*60*60)),0) as avg_time_seconds, round(max(abs(extract(second from elapsed) + extract(minute from elapsed)*60 + extract(hour from elapsed)*60*60 + extract(day from elapsed)*24*60*60)),0) as max_time_seconds from ( select user_id, job_name, start_time, end_time, (end_time - start_time) elapsed; from hsp_job_status where parent_job_id is null and end_time is not null and start_time > to_char(sysdate-7) ) group by job_name order by num_times_run desc
SQL Server:
select job_name, count(job_name) as num_times_run, round(avg(abs(DATEPART(second, elapsed) + datepart(minute, elapsed) + datepart(hour, elapsed) + datepart(day, elapsed))),0) as avg_time_seconds, round(max(abs(DATEPART(second, elapsed) + DATEPART(minute, elapsed) + DATEPART(hour, elapsed) + DATEPART(DAY, elapsed))),0) as max_time_seconds from ( select user_id, job_name, start_time, end_time, datediff(ss,start_time,END_TIME) as elapsed from [dbo].[HSP_JOB_STATUS] where parent_job_id is null and end_time is not null and start_time > GETDATE()-7 ) as ps group by job_name order by num_times_run desc
Sunday, February 9, 2014
Essbase runtime subvars in 11.1.2.3
The Oracle blog has a good explanation of the new runtime subvars functionality available starting in 11.1.2.3. At the end of that post they vaguely hint that it's possible to access this feature from the APIs. So I did a little research into adding the ability to pass runtime subvars from a grid in cubeSavvyLite to a calc script.
SET UPDATECALC off;
SET RUNTIMESUBVARS {
Currmonth = "Jun";
Currlocation = "Florida";
Currproduct="100";
};
FIX(&Currmonth, &Currlocation)
&Currproduct;
ENDFIX
I'd like to point out here that the new runtimesubvars command is very finicky. "SET RUNTIMESUBVARS" (in all capital letters, as above) works, but "SET runtimesubvars" will not even validate.The Scala code (cubeSavvyLite is written in Scala, not Java) to call the "calcSubs" calc script and pass in the runtime subvars is:
val ess: IEssbase = IEssbase.Home.create(IEssbase.JAPI_VERSION)
val dom: IEssDomain = ess.signOn("admin", "password", false, null, "http://apsServer:portNumber/aps/JAPI")
val olapSvr: IEssOlapServer = dom.getOlapServer("serverName")
olapSvr.connect()
val cube: IEssCube = olapSvr.getApplication("Sample").getCube("Basic")
cube.calcFileWithRunTimeSubVars(
false, "calcSubs", "Currmonth=\"Feb\";Currlocation=\"Texas\";Currproduct=\"200\";"
)
olapSvr.disconnect()
Looking at the Sample.Basic log, we see the following entry:Calculating [ Product(200)] with fixed members [Year(Feb); Market(Texas)]
Runtime subvars will be coming soon to cubeSavvyLite. And they will allow you to pass in Page, Row, and Column members from the grid. The grid, in turn, is created from your report script definition.
I'm also looking at making the runtime subvars available in pre-11.1.2.3 versions, as they're really just simple find-and-replaces in the calc script. Please let me know if that's something you'd be interested in having available.
Friday, February 15, 2013
new MaxL "export outline" XML to delimited text parser - orders of magnitude faster
The Java code in my last post works fine for XML containing less than 70,000 members, which is usually sufficient for BSO cubes. ASO cubes, however, can contain a LOT more members. Dan Pressman contacted me earlier in the week to let me know that his XML dimension export file containing 4 million members in almost 90 million lines of XML was taking over 17 hours to run (when it wasn't crashing from running out of memory).
So I rewrote the code to make it more efficient. The same XML above with 90 million lines now takes about 3.5 minutes to run and only uses 75MB of RAM. The functionality is even improved, in that member attributes are now also output. A header line is also prepended, which, due to Java I/O, adds about a minute to the process.
I recommend using this new code for all files instead of the code in the previous post. You can find the two files needed in my GitHub essbase-parse-export-outline-xml-to-text repository.
I also created a very simple Java GUI that allows you to choose the input file, output file, and delimiter:
 You can use the XMLOutlineParser.jar file from the above GitHub repository to launch the GUI. If you have a fairly recent Java jre or jdk installed (version 6 or higher), you should be able to save the jar file to your local drive, then double-click on it to launch the GUI.
You can use the XMLOutlineParser.jar file from the above GitHub repository to launch the GUI. If you have a fairly recent Java jre or jdk installed (version 6 or higher), you should be able to save the jar file to your local drive, then double-click on it to launch the GUI.
P.S. As you can see in the comments, some people have experienced issues when trying to save the output file on Windows. The following steps are the workaround to this permissions issue:
Update: I've added the ability to pass in command line arguments, making XMLOutlineParser suitable for scripting in batch and shell scripts. Passing in arguments will prevent the GUI from running.
So I rewrote the code to make it more efficient. The same XML above with 90 million lines now takes about 3.5 minutes to run and only uses 75MB of RAM. The functionality is even improved, in that member attributes are now also output. A header line is also prepended, which, due to Java I/O, adds about a minute to the process.
I recommend using this new code for all files instead of the code in the previous post. You can find the two files needed in my GitHub essbase-parse-export-outline-xml-to-text repository.
I also created a very simple Java GUI that allows you to choose the input file, output file, and delimiter:
P.S. As you can see in the comments, some people have experienced issues when trying to save the output file on Windows. The following steps are the workaround to this permissions issue:
- Go to Start -> Programs -> Accessories
- right click on Command Prompt and select "Run as administrator"
- cd to the directory where you saved essbase-parse-export-outline-xml-to-text
- run "java -jar XMLOutlineParser.jar"
Update: I've added the ability to pass in command line arguments, making XMLOutlineParser suitable for scripting in batch and shell scripts. Passing in arguments will prevent the GUI from running.
- run java -jar XMLOutlineParser.jar "input file: path & name" "output file: path & name" "field separator to use in output file"
- -------e.g. java -jar XMLOutlineParser.jar "/Users/harry/year.xml" "/Users/harry/Documents/year.txt" "!"
Wednesday, January 30, 2013
Parse MaxL export outline xml to flat file - see next post for updated, faster code
The new (as of 11.1.2) MaxL "export outline" command has made using the Essbase Java API to export outlines obsolete. It is an order of magnitude faster and doesn't run into the typical Essbase japi issue with ports. The only problem is that it exports to XML format. The resulting file is more difficult to use in downstream processes than a delimited text file. It also can't be used to import back into Essbase.
Luckily, however, it is a fairly simple matter to parse the XML to a flat file with a delimiter of your choice:
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileWriter;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.Reader;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Attr;
import org.w3c.dom.Document;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.ErrorHandler;
import org.xml.sax.InputSource;
import org.xml.sax.SAXException;
import org.xml.sax.SAXParseException;
/***
*
* @author Harry Gates
Usage
* 1) Use the MaxL "export outline" command to export a dimension of the outline
* export outline "/path_to_otl/Sample.otl" list dimensions {"Account"} with alias_table "Default" to xml_file "/path_to_save_xml/sample_account_dim.xml";
* 2) Change the delimiter, inputFile, and outputFile
* 3) Compile and run MaxLExportOutlineParseXML.java
*/
public class MaxLExportOutlineParseXML implements ErrorHandler {
public static String delimiter;
public static String inputFile;
public static String outputFile;
public static void main(String[] args) {
delimiter = "?";
inputFile = "/path_to_save_xml/sample_account_dim.xml";
outputFile = "/path_to_save_result/sample_account_dim.txt";
try {
convertXML();
} catch (Exception e) {
e.printStackTrace();
}
}
public static void convertXML() throws Exception {
String output = "";
DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();
builderFactory.setNamespaceAware(false);
builderFactory.setValidating(false);
builderFactory.setIgnoringElementContentWhitespace(true);
DocumentBuilder builder = null;
File file = new File(inputFile);
InputStream inputStream= new FileInputStream(file);
Reader reader = new InputStreamReader(inputStream);
InputSource is = new InputSource(reader);
is.setEncoding("UTF-8");
builder = builderFactory.newDocumentBuilder();
builder.setErrorHandler(new MaxLExportOutlineParseXML());
Document xmlDoc = builder.parse(is);
NodeList mbrNL = xmlDoc.getElementsByTagName("Member");
NodeList dimNL = xmlDoc.getElementsByTagName("Dimension");
String dimName = dimNL.item(0).getAttributes().getNamedItem("name").getNodeValue().replaceAll("\\r\\n|\\r|\\n", " ");
String header = "PARENT0," + dimName + delimiter + "CHILD0," + dimName + delimiter + "ALIAS0," + dimName
+ delimiter + "PROPERTY0," + dimName + delimiter + "FORMULA0," + dimName + delimiter;
int udaCountTotal = 0;
BufferedWriter outputStream;
outputStream = new BufferedWriter(new FileWriter(outputFile));
if (mbrNL.getLength() > 0) {
Node node = null;
for (int i = 0; i < mbrNL.getLength(); i++) {
node = mbrNL.item(i);
if (node.hasChildNodes()) {
String memberName = "";
String parentName = "";
String UDA = "";
String alias = "";
String dataStorage = "";
String timeBalance = "";
String memberFormula = "";
String twoPassCalc = "";
String consolidation = "";
String varianceReporting = "";
int udaCount = 0;
NodeList list = node.getChildNodes();
for (int j = 0; j < list.getLength(); j++) {
if (list.item(j).getNodeName().equals("UDA")) {
UDA += list.item(j).getTextContent().replaceAll("\\r\\n|\\r|\\n", " ") + delimiter;
udaCount++;
}
if (list.item(j).getNodeName().equals("Alias")) {
alias = list.item(j).getTextContent().replaceAll("\\r\\n|\\r|\\n", " ").replaceAll("\"", " ");
}
}
udaCountTotal = udaCount > udaCountTotal ? udaCount : udaCountTotal;
NamedNodeMap nodAttrs = node.getAttributes();
for (int k = 0; k < nodAttrs.getLength(); k++) {
Attr nodAttr = (Attr)nodAttrs.item(k);
String nodName = nodAttr.getNodeName();
if (nodName.equals("name")) {
parentName = node.getParentNode().getAttributes().getNamedItem("name").getNodeValue().replaceAll("\\r\\n|\\r|\\n", " ");
memberName = node.getAttributes().getNamedItem("name").getNodeValue().replaceAll("\\r\\n|\\r|\\n", " ");
parentName = parentName.replaceAll("\"", " ");
memberName = memberName.replaceAll("\"", " ");
} else if (nodName.equals("Consolidation")) {
consolidation = nodAttr.getNodeValue().replaceAll("\"", " ");
consolidation = consolidation.trim();
} else if (nodName.equals("DataStorage")) {
dataStorage = nodAttr.getNodeValue().replaceAll("\"", " ");
if (dataStorage.equals("DynamicCalc")) {
dataStorage = "X";
} else if (dataStorage.equals("DynamicCalcAndStore")) {
dataStorage = "V";
} else if (dataStorage.equals("LabelOnly")) {
dataStorage = "O";
} else if (dataStorage.equals("NeverShare")){
dataStorage = "N";
} else if (dataStorage.equals("ShareData")){
dataStorage = "";
}
dataStorage = dataStorage.trim();
} else if (nodName.equals("MemberFormula")) {
memberFormula = nodAttr.getNodeValue();
} else if (nodName.equals("TwoPassCalc")) {
twoPassCalc = nodAttr.getNodeValue().replaceAll("\"", " ");
twoPassCalc = twoPassCalc.equals("Y") ? "T" : twoPassCalc;
twoPassCalc = twoPassCalc.trim();
} else if (nodName.equals("TimeBalance")) {
timeBalance = nodAttr.getNodeValue().replaceAll("\"", " ");
if (timeBalance.equals("Last")) {
timeBalance = "L";
} else if (timeBalance.equals("First")) {
timeBalance = "F";
} else if (timeBalance.equals("Average")) {
timeBalance = "A";
}
timeBalance = timeBalance.trim();
} else if (nodName.equals("VarianceReporting")) {
varianceReporting = nodAttr.getNodeValue().replaceAll("\"", " ");
varianceReporting = varianceReporting.equals("Expense") ? "E" : varianceReporting;
varianceReporting = varianceReporting.trim();
} else {
System.out.println(nodAttr.getNodeName() + ": " + nodAttr.getNodeValue());
}
}
consolidation = consolidation.equals("") ? "+" : consolidation;
consolidation = consolidation.equals("") ? "" : " " + consolidation;
timeBalance = timeBalance.equals("") ? "" : " " + timeBalance;
dataStorage = dataStorage.equals("") ? "" : " " + dataStorage;
twoPassCalc = twoPassCalc.equals("") ? "" : " " + twoPassCalc;
varianceReporting = varianceReporting.equals("") ? "" : " " + varianceReporting;
String properties = consolidation + timeBalance + dataStorage + twoPassCalc + varianceReporting;
output += parentName.replaceAll(" +", " ").trim()
+ delimiter + memberName.replaceAll(" +", " ").trim()
+ delimiter + alias.replaceAll(" +", " ").trim()
+ delimiter + properties.trim()
+ delimiter + memberFormula
+ delimiter + UDA.replaceAll(" +", " ").trim() + "\n";
}
}
}
System.out.println("udaCountTotal: " + udaCountTotal);
String udaHeader = "";
for (int i = 0; i < udaCountTotal; i++) {
udaHeader += "UDA0," + dimName + delimiter;
}
header += udaHeader;
output = header + "\n" + output;
outputStream.append(output);
outputStream.close();
}
public void fatalError(SAXParseException spe) throws SAXException {
System.out.println("Fatal error at line " + spe.getLineNumber());
System.out.println(spe.getMessage());
throw spe;
}
public void warning(SAXParseException spe) {
System.out.println("Warning at line " + spe.getLineNumber());
System.out.println(spe.getMessage());
}
public void error(SAXParseException spe) {
System.out.println("Error at line " + spe.getLineNumber());
System.out.println(spe.getMessage());
}
}
Subscribe to:
Posts (Atom)